
近日,我院作为通讯作者单位联合中国科学技术大学与科大讯飞公司的研究成果《MedTEB & CARE: Benchmarking and Enabling Efficient Chinese Medical Retrieval via Asymmetric Encoders》成功发表于国际顶级学术会议ACL(Association for Computational Linguistics),我院丁克玉副教授为该成果唯一通讯作者。该会议是自然语言处理与计算语言学领域的国际顶级学术会议,属于中国计算机学会(CCF)认定的A类国际学术会议,在自然语言处理领域享有极高声誉,代表着该领域的国际前沿水平,自创办以来始终是全球NLP 领域科研成果展示、学术交流与技术碰撞的核心平台。ACL 2026(第64 届国际计算语言学协会年会)将于2026 年7 月2 日至7 月7 日在美国加利福尼亚州圣地亚哥举办。
随着人工智能技术在医疗领域的深度应用,精准、高效的医疗文本检索成为提升临床决策支持、缓解LLM(大语言模型)幻觉问题的关键。然而,当前中文医疗文本嵌入领域面临两大核心挑战:一是缺乏全面、高保真的基准测试数据集,现有数据集存在标注稀疏、假阴性率高、缺乏专家验证等问题,严重阻碍了相关研究的推进;二是现有LLM 基嵌入模型虽具备较强检索能力,但latency 高、计算成本高,难以适配实时医疗问答等latency 敏感场景,难以实现检索精度与推理效率的平衡。
针对上述行业痛点,我院科研团队与合作单位联合攻关,构建了首个全面、高质量的中文医疗文本嵌入基准测试集MedTEB(Chinese Medical Text Embedding Benchmark),并提出了高效的中文医疗非对称检索模型CARE(Chinese Medical Asymmetric REtriever),为中文医疗文本检索与知识图谱构建提领域供了全新的解决方案。
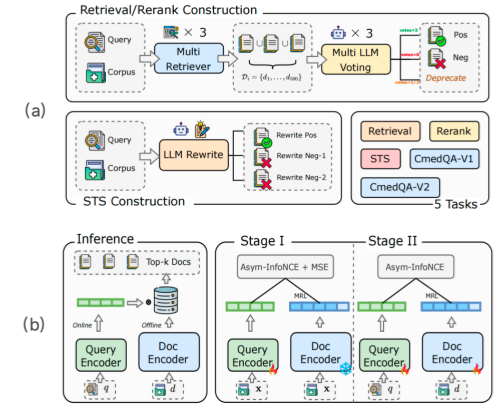
图一:(a)展示了构建MedTEB 基准的工作流程,描述了用于判别性任务(检索/重排序)和语义相似性任务(STS)的差异化策展策略。
(b)展示非对称嵌入模型的推理与训练流程。第一阶段:通过Asym-InfoNCE 和MSE 损失函数对查询编码器进行训练,使其与冻结文档编码器实现匹配。第二阶段:同时利用Asym-InfoNCE 损失函数对两个编码器进行联合微调,以优化检索数据的表现。
该成果的数据和代码已经开源https://github.com/PhilipGAQ/CARE,模型也已经开源 https://huggingface.co/PhilipGAQ/CARE-0.3B-4,https://huggingface.co/PhilipGAQ/CARE-0.3B-8B。
